新手教程丨gpt-oss-120b模型本地部署!
gpt-oss-120b是OpenAI在今年8月推出的高性能AI开源大模型,专为复杂推理任务场景设计,满足端侧设备本地推理的需求。
如果您需要在thor上运行该模型,可以联系销售进行说明,设备将会在出厂时预装大模型,方便您开机即用。

接下来手把手教大家如何在品立自研Jetson Thor系列具身智能算力平台(Y-C28-DEV/28F1E4)上本地部署运行gpt-oss-120b大模型。
01、部署gpt-oss-120b大模型
使用Docker(ollama)进行gpt-oss-120b模型本地部署
步骤1:上电开机
给品立Y-C28-DEV/28F1E4连接显示、输入、网线,上电开机。如没有特殊要求,系统是纯净版本,软件需自行安装。使用以下命令安装jetpack7。
sudo apt update
sudo apt install nvidia-jetpack步骤2:安装docker
sudo apt update
sudo apt install -y nvidia-container curl
curl https://get.docker.com | sh && sudo systemctl --now enable docker
sudo nvidia-ctk runtime configure --runtime=docker
步骤3:在docker中安装ollama
mkdir ~/ollama-data/
sudo docker run -it -p 11434:11434 --runtime=nvidia --name ollama -v ${HOME}/ollama-data:/data ghcr.io/nvidia-ai-iot/ollama:r38.2.arm64-sbsa-cu130-24.04

命令详解:
--runtime=nvidia
在容器中使用gpu加速
-p 11434:11434
将容器内的 11434 端口(Ollama 默认端口)映射到主机的 11434 端口,该参数是为了在Cherry-Studio中调用ollama,如不需要Cherry-Studio删掉该参数即可。
-v ${HOME}/ollama-data:/data
将主机的${HOME}/ollama-data 目录(即当前用户家目录下的ollama-data文件夹)挂载到容器内的/data目录,持久化存储Ollama的模型数据和配置,容器删除后数据不会丢失,请根据所需情况配置。
步骤4:模型拉取和运行
ollama pull gpt-oss:120b
ollama run --verbose gpt-oss:120b
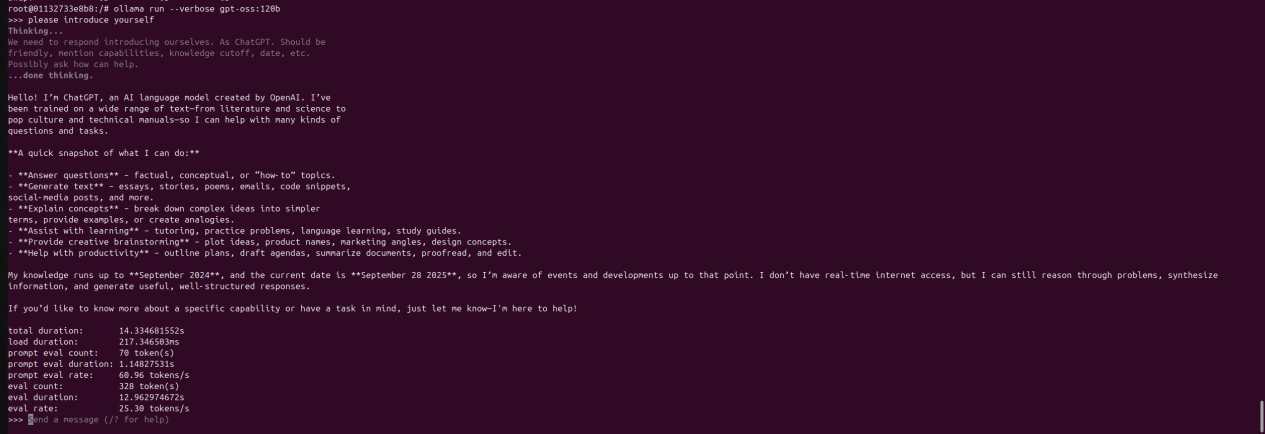
▲速度25 tokens/s,该速度为使用gpu加速后的普通速度,可根据需求调节相关参数来增大该速度值。
结束对话:
/bye退出容器:
exit
重启容器:
sudo docker restart ollama
再次进入容器:
sudo docker exec -it ollama /bin/bash
02、安装Cherry-Studio软件
通过前面的操作已经完成gpt-oss-120b模型的部署,并且可以通过命令行进行使用。
但为了更方便的使用该模型,这里提供一个可视化的交互工具——Cherry Studio,它借助多模型聚合技术、本地化部署方案和全流程自动化处理,重构人机协作方式,可以显著提升复杂任务的处理效率。以下是该软件的安装教程。
在官网下载arm版本的安装包,并传输到设备上,执行安装命令。
chmod +x Cherry-Studio-1.5.9-arm64.deb
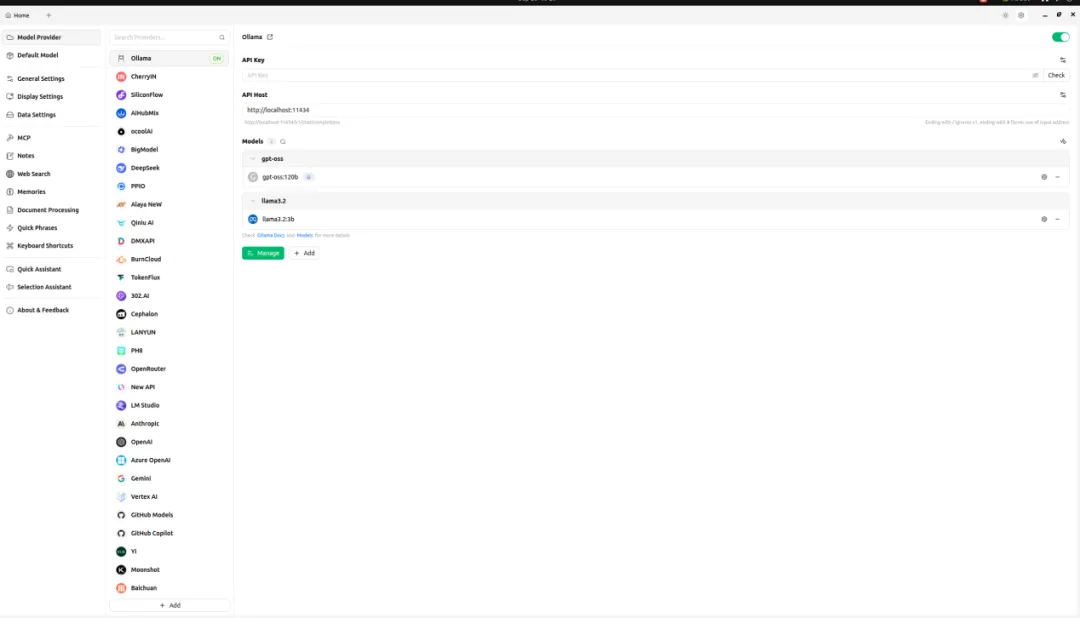
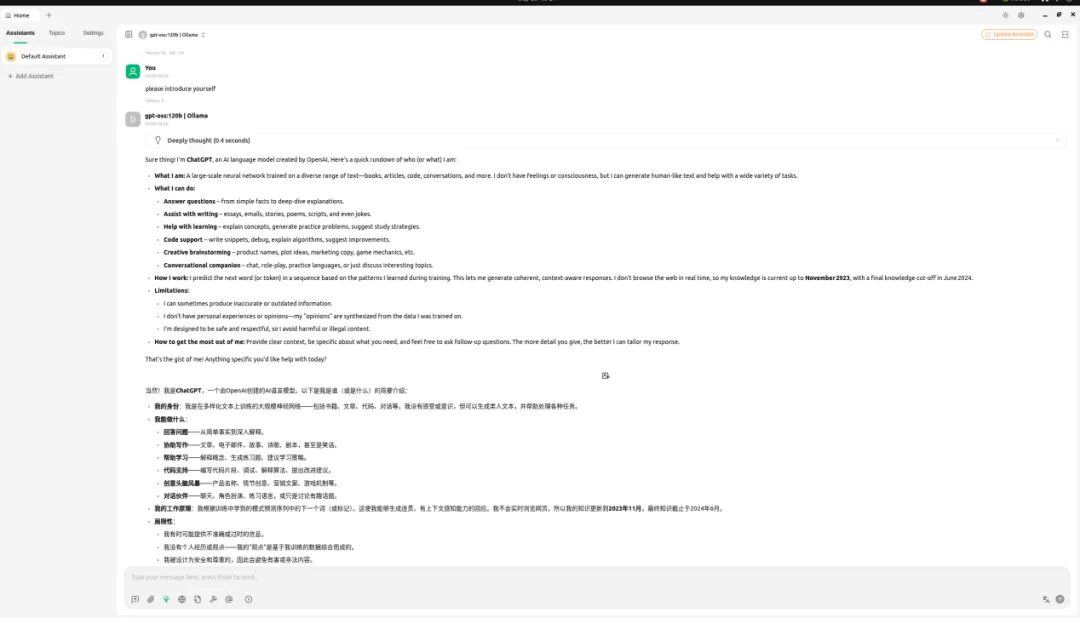
sudo dpkg -i Cherry-Studio-1.5.9-arm64.deb点击屏幕左下角,找到cherry-studio,双击打开,点击设置,找到ollama,就可以看到刚才安装成功的gpt-oss-120b模型,选中gpt-oss-120b模型,点击home,就可以使用了。
03、常见问题说明
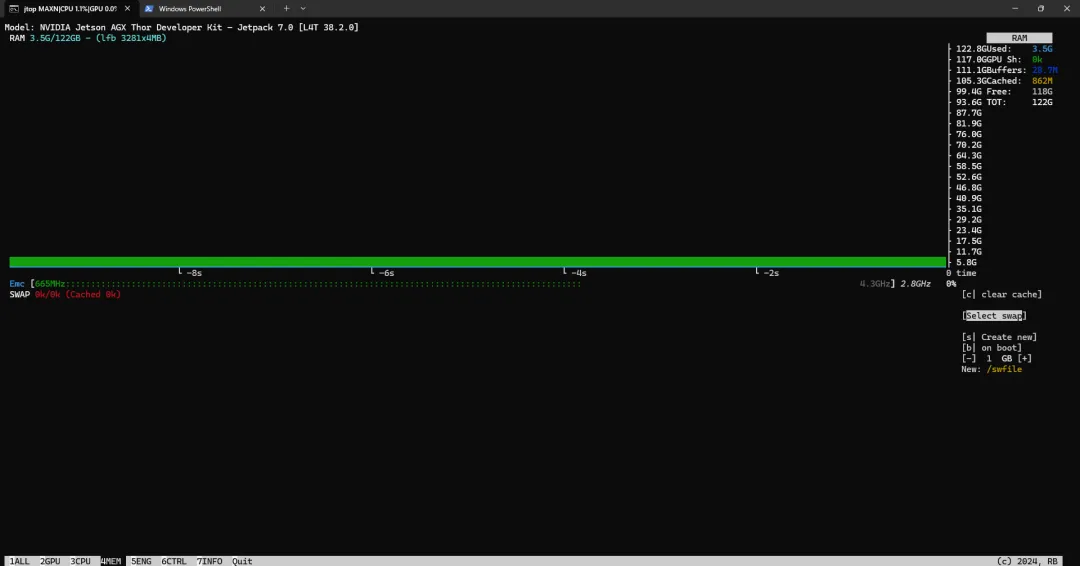
Memory不足
1.sudo jtop;
2.按4;
3.按c清除缓存;
4.按q退出。